
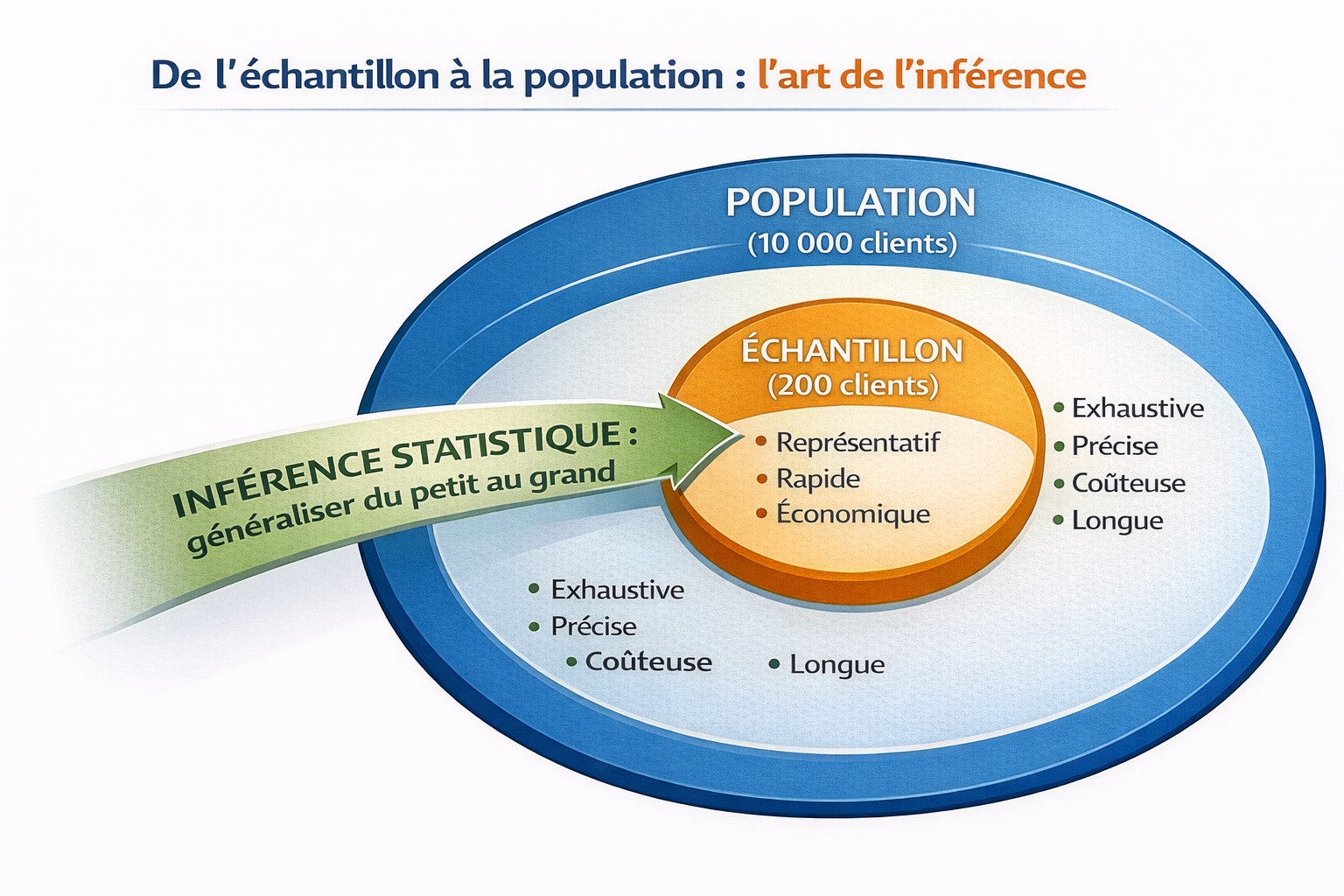
Imaginez cette situation : vous dirigez une entreprise de 10 000 clients. Vous voulez connaître leur niveau de satisfaction pour améliorer vos services.
Problème : il est impossible (ou trop coûteux) d'interroger les 10 000 clients.
Solution : vous en interrogez 200, choisis intelligemment.
Mais voici la question à 1 million de FCFA :
Ces 200 clients représentent-ils vraiment les 10 000 ? Ou avez-vous interrogé, sans le savoir, uniquement les plus satisfaits ? Ou uniquement ceux de Douala ? Ou uniquement les plus jeunes ?
Si votre échantillon est biaisé, toutes vos conclusions seront fausses. Et les décisions que vous prendrez ensuite risquent de vous coûter cher.
Cette leçon est absolument stratégique. Elle va vous apprendre à :
- Faire la différence entre population et échantillon
- Identifier les pièges invisibles qui faussent vos données
- Déterminer combien d'observations vous avez vraiment besoin
C'est la base de toute collecte de données fiable. Alors installez-vous confortablement, et découvrons ensemble comment éviter ces erreurs qui coûtent des fortunes aux entreprises.
Population vs échantillon : bien faire la différence
Commençons par le commencement. Deux mots que vous allez utiliser en permanence dans votre pratique de la data.
La population
Définition simple :
La population, c'est l'ensemble COMPLET, TOTAL, EXHAUSTIF des éléments concernés par votre étude.
C'est votre "univers d'analyse". Tout ce qui vous intéresse, sans exception.
Exemples concrets :
Exemple 1 : Analyse commerciale
Vous voulez analyser le comportement d'achat de vos clients.
→ Population = TOUS vos clients actifs depuis janvier 2024
Exemple 2 : Contrôle qualité
Vous voulez vérifier la qualité de vos produits fabriqués le mois dernier.
→ Population = TOUS les produits fabriqués en décembre 2024
Exemple 3 : Gestion RH
Vous voulez mesurer la satisfaction de vos employés.
→ Population = TOUS les employés actuellement en poste dans l'entreprise
Exemple 4 : Analyse de ventes
Vous voulez étudier les transactions du trimestre.
→ Population = TOUTES les transactions enregistrées entre octobre et décembre 2024
Les avantages de travailler sur la population complète :
- Précision absolue : aucune incertitude, aucune marge d'erreur
- Pas de risque de biais : vous avez tout sous les yeux
- Résultats définitifs : ce ne sont pas des estimations, ce sont des faits
Les limites (et pourquoi on ne peut pas toujours le faire) :
- Temps : interroger 50 000 clients peut prendre des mois
- Coût : chaque enquête, chaque contrôle a un prix
- Faisabilité : parfois, c'est techniquement impossible (exemple : tester la résistance de TOUS vos produits les détruirait tous !)
C'est là qu'intervient l'échantillon.
L'échantillon
Définition simple :
Un échantillon, c'est un sous-ensemble représentatif de la population.
Vous prenez une partie, mais une partie qui "ressemble" au tout.
Pourquoi échantillonner ?
Trois raisons principales :
1. Contrainte de temps
Vous avez besoin d'une réponse rapidement. Interroger 200 clients prend une semaine, interroger 10 000 clients prendrait 6 mois.
2. Contrainte de coût
Chaque enquête a un prix (appels, SMS, incentives). Multiplier par 10 000 peut exploser votre budget.
3. Contrainte de faisabilité
Parfois, accéder à toute la population est tout simplement impossible. Exemple : vous ne pouvez pas tester la durée de vie de TOUTES vos ampoules en les laissant allumées jusqu'à extinction (vous n'auriez plus rien à vendre !).
Le principe clé : la représentativité
Un bon échantillon doit être un "mini-portrait" fidèle de la population.
Si votre population de clients est composée de :
- 60% de femmes et 40% d'hommes
- 30% à Douala, 25% à Yaoundé, 20% à Abidjan, 25% ailleurs
- 40% de clients Bronze, 35% Argent, 25% Or
Alors votre échantillon devrait refléter ces mêmes proportions.
Exemple visuel :
Imaginez un grand sac de billes de différentes couleurs (votre population). Si vous en prenez une poignée au hasard (votre échantillon), cette poignée doit contenir à peu près les mêmes proportions de couleurs que le sac complet.
📦 EN PRATIQUE — Population ou échantillon ?
Avant toute analyse, posez-vous cette question simple :
"Ai-je accès à TOUTES les données qui m'intéressent, ou seulement à une partie ?"
- Si TOUTES → vous travaillez sur la population
- Si une partie → vous travaillez sur un échantillon
Conséquence importante :
Avec une population, vous énoncez des certitudes :
"45% de nos clients sont des femmes."
Avec un échantillon, vous faites des estimations :
"Selon notre échantillon de 200 clients, nous estimons que 45% de l'ensemble de nos clients sont des femmes, avec une marge d'erreur de ±7%."
Vous voyez la nuance ? C'est fondamental.
✅ À RETENIR
Quand vous analysez un échantillon, vous faites une inférence statistique : vous généralisez à partir d'une partie. D'où l'importance absolue de bien choisir cette partie.
C'est précisément là que se cachent les pièges. Voyons-les ensemble.
Biais d'échantillonnage : le piège invisible
Un biais d'échantillonnage, c'est un peu comme avoir des lunettes déformantes sans le savoir. Vous regardez vos données, elles vous semblent claires... mais en réalité, vous voyez une version déformée de la vérité.
Et le pire ? Vous ne vous en rendez même pas compte.
C'est pour cela que tant d'entreprises prennent de mauvaises décisions malgré des montagnes de données. Leurs données sont biaisées dès le départ.
— Qu'est-ce qu'un biais d'échantillonnage ?
Définition simple :
Un biais d'échantillonnage se produit quand votre échantillon ne représente pas fidèlement la population que vous voulez étudier.
En d'autres termes : votre "mini-portrait" ne ressemble pas du tout au tableau complet.
Conséquence :
Toutes vos conclusions, tous vos calculs, toutes vos décisions seront faussés.
Exemple frappant :
Vous voulez connaître le revenu moyen de vos clients. Vous interrogez 100 personnes... mais uniquement celles qui viennent dans votre boutique premium du centre-ville.
Résultat : vous concluez que vos clients gagnent en moyenne 500 000 FCFA/mois.
Problème : vous avez oublié tous les clients qui achètent en ligne, dans vos boutiques de quartier, ou via les revendeurs. Leur revenu moyen est peut-être de 200 000 FCFA/mois.
Votre échantillon est biaisé vers le haut. Vos conclusions sont fausses.
— Les principaux types de biais (et comment les éviter)
Voyons ensemble les 4 biais les plus fréquents. Je vous garantis qu'au moins un de ces pièges vous guette dans votre prochain projet d'analyse.
BIAIS 1 : Le biais de sélection
Définition :
Vous sélectionnez (volontairement ou non) certaines personnes plutôt que d'autres, de façon non aléatoire.
Exemple classique :
Vous envoyez un questionnaire de satisfaction uniquement aux clients qui ont effectué un achat récent.
Problème :
Vous ratez complètement les clients mécontents qui ont arrêté d'acheter chez vous ! Votre satisfaction va paraître artificiellement élevée.
Autre exemple :
Vous interrogez uniquement les clients qui répondent rapidement à votre email. Or, ceux qui répondent rapidement sont souvent les plus engagés (positivement ou négativement). Les indifférents ne répondent pas.
Solution :
Utilisez un échantillonnage aléatoire : chaque membre de la population doit avoir la même chance d'être sélectionné.
En pratique :
- Attribuez un numéro à chaque client
- Utilisez un générateur de nombres aléatoires (Excel, calculatrice)
- Sélectionnez les clients correspondant aux numéros tirés
Formule Excel simple :
=ALEA.ENTRE.BORNES(1; 10000) pour tirer un nombre au hasard entre 1 et 10 000.
BIAIS 2 : Le biais de non-réponse
Définition :
Toutes les personnes de votre échantillon ne répondent pas. Et celles qui ne répondent pas sont souvent différentes de celles qui répondent.
Exemple concret :
Vous envoyez un questionnaire en ligne sur la satisfaction au travail. Vous obtenez 30% de réponses.
Problème :
Qui répond généralement ?
- Les très satisfaits (qui veulent le faire savoir)
- Les très mécontents (qui veulent se plaindre)
Qui ne répond PAS ?
- Les indifférents (la majorité silencieuse)
- Les trop occupés
- Les démotivés
Votre échantillon ne reflète plus la réalité. Vous avez perdu la voix de la majorité.
Solution :
- Viser un taux de réponse élevé (minimum 50%, idéalement 70%+)
- Relancer les non-répondants
- Offrir un incentive (cadeau, tirage au sort)
- Comparer les profils des répondants vs non-répondants pour détecter le biais
BIAIS 3 : Le biais de volontariat
Définition :
Vous demandez "qui veut participer ?" et seuls les volontaires sont dans votre échantillon.
Exemple :
"Nous recherchons des clients pour tester notre nouveau produit. Qui est intéressé ?"
Problème :
Qui se porte volontaire ?
- Les fans de votre marque (déjà convaincus)
- Les curieux (profil atypique)
- Les chercheurs de gratuits
Vous ratez complètement le client "normal" qui ne se porte jamais volontaire mais qui représente 80% de votre clientèle.
Solution :
Privilégier la sélection aléatoire plutôt que le volontariat. Si vous devez utiliser des volontaires, soyez conscient que vos résultats seront biaisés vers les profils "engagés".
BIAIS 4 : Le biais géographique ou temporel
Définition :
Vous collectez vos données uniquement dans certains lieux ou à certains moments, créant une distorsion.
Exemple géographique :
Vous interrogez vos clients uniquement à Douala.
Problème :
Les clients de Yaoundé, Bafoussam, ou des zones rurales ont peut-être des besoins et comportements complètement différents. Vos conclusions ne seront valables que pour Douala.
Exemple temporel :
Un restaurant qui interroge ses clients uniquement le vendredi soir (jour de forte affluence, ambiance festive, clientèle différente).
Problème :
Le vendredi soir n'est PAS représentatif des autres jours. Le lundi midi, c'est peut-être une tout autre clientèle avec d'autres attentes.
Solution :
- Varier les zones géographiques : représenter toutes vos régions de vente
- Varier les moments : jours de semaine, week-end, matin, soir, haute/basse saison
- Stratifier votre échantillon si nécessaire

— Cas pratique commenté
Mettons tout cela en pratique avec un cas concret.
SITUATION
Vous gérez un restaurant à Yaoundé. Vous voulez évaluer la satisfaction de vos clients pour améliorer votre service.
❌ MAUVAISE APPROCHE (échantillon biaisé)
Vous décidez d'interroger vos clients le vendredi soir uniquement, à la sortie du restaurant, en leur demandant "Voulez-vous répondre à un petit sondage ?"
Analyse des biais :
-
Biais temporel : Le vendredi soir, c'est l'ambiance festive, les groupes d'amis, l'atmosphère détendue. Ce n'est PAS représentatif des autres jours.
-
Biais de sélection : À la sortie du restaurant, vous interrogez uniquement ceux qui sont restés jusqu'au bout. Les clients mécontents sont peut-être partis plus tôt.
-
Biais de volontariat : En demandant "Voulez-vous répondre ?", vous obtenez surtout les très satisfaits (qui veulent vous féliciter) et les très mécontents (qui veulent se plaindre). Les neutres disent "non merci, je suis pressé".
Résultat :
Vos conclusions seront complètement faussées. Vous risquez de croire que tout va bien... alors qu'une partie importante de votre clientèle est insatisfaite.
✅ MEILLEURE APPROCHE (échantillon représentatif)
Voici comment procéder intelligemment :
1. Définir clairement votre population
→ Tous les clients ayant mangé au restaurant au cours du mois dernier
2. Varier les jours et créneaux
→ Interroger des clients le lundi midi, mardi soir, jeudi midi, vendredi soir, samedi midi, dimanche soir...
3. Sélectionner aléatoirement
→ Par exemple : "Nous allons interroger 1 client sur 5 qui vient payer l'addition"
4. Utiliser plusieurs canaux
→ Sur place + par SMS après la visite + par email
5. Viser un bon taux de réponse
→ Offrir un café gratuit pour la prochaine visite en échange de la réponse
Résultat :
Vous obtenez un échantillon qui représente vraiment votre clientèle dans sa diversité. Vos conclusions seront fiables et vos décisions d'amélioration seront pertinentes.
⚠️ ATTENTION
Le biais le plus dangereux est celui que vous ne voyez pas.
Avant de collecter vos données, posez-vous TOUJOURS cette question :
"Qui est-ce que je risque d'oublier dans mon échantillon ?"
- Les clients mécontents qui ne reviennent plus ?
- Les clients des zones rurales ?
- Les clients qui achètent en ligne ?
- Les employés des équipes de nuit ?
- Les nouveaux clients vs les anciens ?
Cette simple question peut vous sauver d'erreurs catastrophiques.
Taille d'échantillon : quand est-ce "suffisant" ?
Maintenant que vous savez éviter les biais, une question se pose naturellement :
"Combien de personnes dois-je interroger pour que mes conclusions soient fiables ?"
C'est une excellente question. Et la réponse est : ça dépend.
Mais rassurez-vous, il existe des règles simples pour vous guider.
— Le principe de base
Règle fondamentale :
Plus votre échantillon est grand, plus vos estimations seront précises.
C'est logique : si vous interrogez 10 clients sur 10 000, vous avez très peu de chances de représenter la réalité. Si vous en interrogez 500, c'est déjà beaucoup mieux.
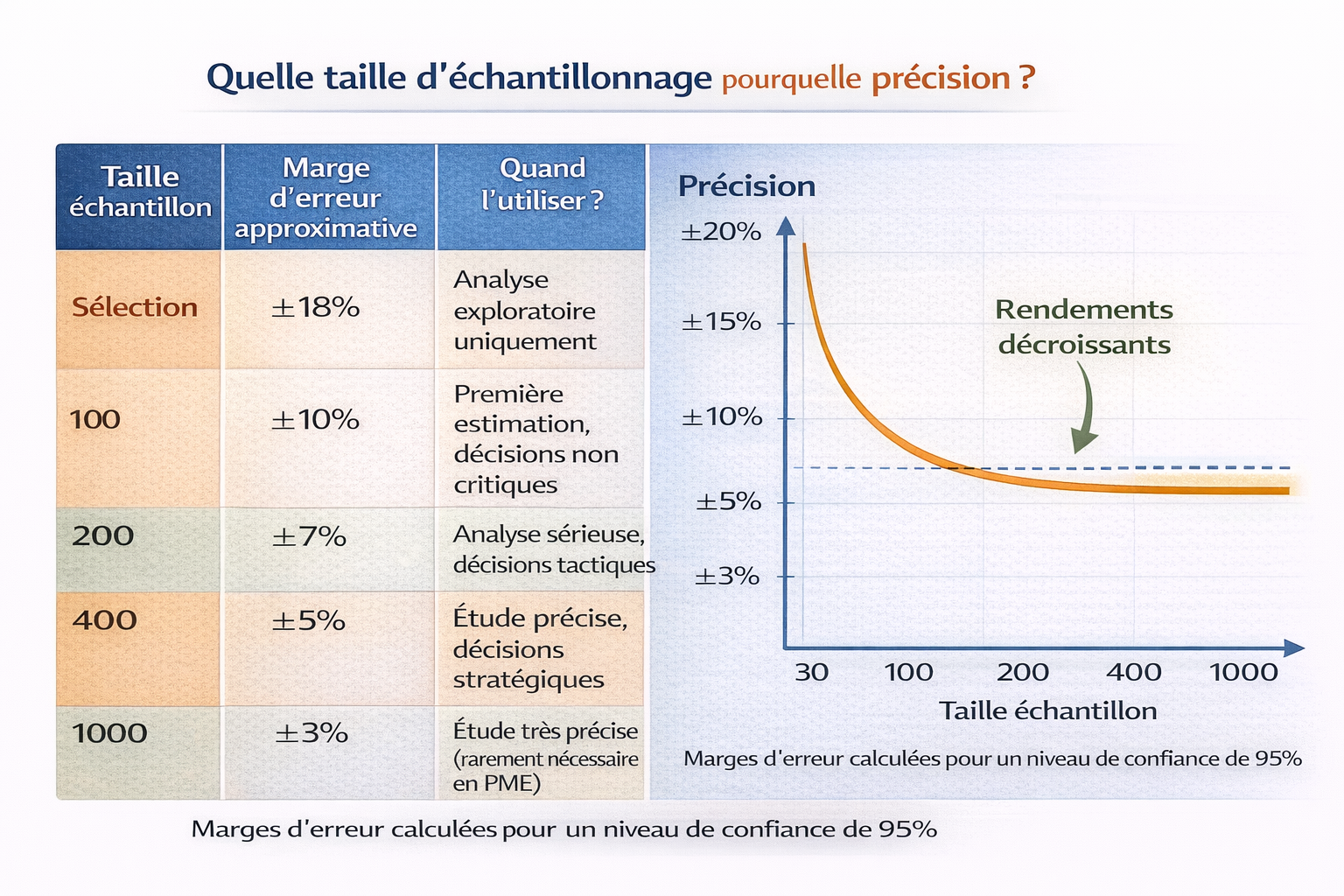
MAIS : les rendements décroissants
Voici un principe statistique important : l'amélioration de la précision diminue à mesure que vous augmentez la taille.
En clair :
- Passer de 10 à 100 observations apporte un énorme gain de précision
- Passer de 100 à 200 apporte encore un bon gain
- Passer de 1000 à 2000 apporte très peu de gain supplémentaire
Graphique mental à retenir :
La précision augmente rapidement au début, puis se stabilise. Au-delà d'un certain seuil, ajouter des observations coûte cher pour peu de bénéfice.
— Règles simples pour débuter
Si vous débutez en data et que vous ne voulez pas vous perdre dans des calculs complexes, voici des règles de bon sens qui fonctionnent dans 80% des cas :
Règle 1 : Le minimum statistique
→ Au moins 30 observations pour commencer à avoir des résultats exploitables
Pourquoi 30 ? C'est une règle statistique de base liée au "théorème central limite". En dessous de 30, vos calculs de moyenne et d'écart-type sont peu fiables.
Règle 2 : Pour une enquête représentative
→ 100 à 200 observations bien sélectionnées suffisent souvent pour une première analyse fiable
Si votre échantillon est bien randomisé et sans biais, 200 réponses vous donnent déjà une bonne image de votre population.
Règle 3 : Pour des sous-groupes
→ 30 observations minimum par segment que vous voulez analyser
Exemple : si vous voulez comparer hommes vs femmes, visez au moins 30 hommes ET 30 femmes, soit 60 au total minimum.
Règle 4 : Pour les grandes populations
→ Au-delà de 10 000 individus dans votre population, la taille de l'échantillon dépend moins de la taille de la population que de la précision souhaitée
En clair : interroger 400 personnes sur 10 000 ou sur 1 million donne quasiment la même précision.
— Ce qui influence la taille nécessaire
Trois facteurs principaux déterminent combien d'observations vous avez besoin :
Facteur 1 : La variabilité des données
Si vos données sont très homogènes (peu de variation), vous avez besoin de moins d'observations.
Exemple :
Vous vendez un seul produit à un prix fixe → peu de variabilité → petit échantillon suffit
Vous vendez 500 produits différents avec des prix de 1000 à 500 000 FCFA → forte variabilité → échantillon plus grand nécessaire
Facteur 2 : Le niveau de précision souhaité
Plus vous voulez être précis, plus vous avez besoin d'observations.
Exemple :
- Marge d'erreur acceptable de ±10% → 100 observations peuvent suffire
- Marge d'erreur de ±3% → vous aurez besoin de 1000+ observations
Facteur 3 : La taille de la population
Contrairement à ce qu'on pense, la taille de la population a moins d'impact qu'on ne le croit.
Exemple contre-intuitif :
Pour une population de 1000 personnes avec une marge d'erreur de ±5%, vous avez besoin d'environ 280 réponses.
Pour une population de 100 000 personnes avec la même marge d'erreur, vous avez besoin de... 383 réponses.
La différence est bien moindre qu'on ne l'imagine !
📦 EN PRATIQUE — Votre guide de lancement
Avant de lancer une collecte de données, suivez ces 4 étapes :
Étape 1 : Définir clairement votre population cible
"Je veux étudier : tous mes clients ayant acheté au moins une fois depuis janvier 2024"
Étape 2 : Choisir une méthode d'échantillonnage
Privilégier l'aléatoire simple si possible (chaque individu a la même chance d'être sélectionné)
Étape 3 : Déterminer votre taille d'échantillon
- Pour une première analyse : viser 100-200 réponses
- Pour une étude plus précise : viser 300-400 réponses
- Pour des sous-groupes : au moins 30 par segment
Étape 4 : Documenter votre méthode
Notez :
- Taille de la population
- Taille de l'échantillon
- Méthode de sélection (aléatoire, stratifiée...)
- Taux de réponse obtenu
- Biais potentiels identifiés
Pourquoi documenter ? Pour pouvoir justifier vos conclusions et permettre à d'autres de vérifier votre travail.
— Exemple chiffré simple
Prenons un cas concret pour illustrer tout cela.
CONTEXTE
Vous avez une base de 5000 clients. Vous voulez connaître leur taux de satisfaction.
QUESTION
Combien de clients devez-vous interroger ?
RÉPONSE (simplifiée)
Option 1 : Échantillon de 100 clients (choisis aléatoirement)
→ Marge d'erreur : environ ±10% (avec 95% de confiance)
Traduction : Si votre échantillon montre 70% de satisfaction, la vraie valeur pour l'ensemble de vos 5000 clients se situe probablement entre 60% et 80%.
Option 2 : Échantillon de 400 clients
→ Marge d'erreur : environ ±5%
Traduction : Si votre échantillon montre 70% de satisfaction, la vraie valeur se situe probablement entre 65% et 75%.
Quelle option choisir ?
Cela dépend de vos besoins :
- Si vous voulez juste avoir une idée générale → 100 clients suffisent
- Si vous devez prendre des décisions stratégiques importantes → visez 400 clients pour plus de précision
Le message clé :
Il n'est pas nécessaire d'interroger des milliers de personnes pour avoir des résultats fiables. Quelques centaines bien sélectionnées suffisent largement.
⚠️ ATTENTION — Ce qui compte encore plus que la taille
Voici une vérité qu'on oublie trop souvent :
Un échantillon de 1000 personnes MAL sélectionné (biaisé) donnera de PIRES résultats qu'un échantillon de 100 personnes BIEN sélectionné (sans biais).
La qualité de votre échantillon (absence de biais) est plus importante que sa taille.
Mieux vaut 150 réponses vraiment représentatives que 2000 réponses biaisées.
Félicitations ! Vous venez de franchir la dernière étape de cette section fondamentale.
Vous savez maintenant :
- Faire la différence entre population et échantillon
- Identifier et éviter les biais qui faussent vos conclusions
- Déterminer combien d'observations vous avez vraiment besoin
Récapitulons les 3 points clés :
1. Population vs échantillon
→ Travailler sur une population = certitudes / Travailler sur un échantillon = estimations avec marge d'erreur
2. Les biais sont vos pires ennemis
→ Biais de sélection, non-réponse, volontariat, géographique/temporel
→ Toujours se demander : "Qui est-ce que je risque d'oublier ?"
3. La taille compte, mais la qualité compte plus
→ Viser 100-200 observations minimum pour une première analyse
→ Privilégier un petit échantillon bien construit plutôt qu'un grand échantillon biaisé
🎯 MESSAGE IMPORTANT
Avec ces trois leçons, vous avez posé des fondations solides :
✅ Vous comprenez pourquoi la statistique est indispensable ✅ Vous savez identifier ce que vous mesurez ✅ Vous maîtrisez comment collecter vos données sans biais
Vous êtes maintenant armé pour collecter et lire vos données avec un œil critique.
C'est la base de toute analyse fiable. Sans ces fondations, même les calculs les plus sophistiqués ne valent rien.
Et maintenant ?
Vous avez les bases. Vous savez QUOI mesurer et COMMENT le collecter.
La prochaine étape naturelle est d'apprendre à DÉCRIRE vos données de façon claire et parlante.
Comment calculer une moyenne qui a du sens ? Qu'est-ce qu'une médiane et quand l'utiliser ? Comment mesurer la dispersion de vos données ? Comment créer des graphiques qui racontent une histoire ?
C'est tout l'objet de la Section 2 : Statistique descriptive.
Vous allez apprendre à transformer vos tableaux de chiffres bruts en insights clairs et actionnables.